简介
离开之前的公司快4个月了,现在整理一下以前干的东西.算是扔出一点儿干货吧 :) 之前的博客发表过一篇了,这里是技术博客,技术博客! 之前没有专门研究过大数据和机器学习,但是也做了不少东西都是现学现卖,成果还是可以的. 语言是自己认为比较反人类的语言 Scala.
工作环境:
- Scala IED
- Scala 2.10.6
- Apache Spark 1.6.1
- Apache Zepplin
这些版本要对应起来,要不然吃不了兜着走。这里集群的管理工具是ambari, 这个工具可以让你轻松的管理集群.
这里我们用的是 Spark on Yarn 模式,其中进行提交任务又有两种模式,这里简单的说一句,这两种模式分别为:
yarn-cluster : driver运行在container之中,所有的日志本地看不到,只能看到running的信息。
yarn-client : drivier运行在client中,可以看到所有的日志,测试比较方便.
机器学习分为两个比较大的步骤: 收集预处理数据;进行学习
收集预处理数据
这里当然选择到处都看得到的数据了,比如法国政府的 一些数据,https://www.data.gouv.fr/fr/datasets/boamp/ 这里好多数据,这里挑选他们的招标信息。这里选择2016年的,进行处理和学习。文件是tgz格式的,利用命令解压,最后得到一堆xml文件,对于这些文件可以利用 https://github.com/databricks/spark-xml 进行处理,处理方式很简单。
命令方式引用外部库
$SPARK_HOME/bin/spark-shell --packages com.databricks:spark-xml_2.10:0.4.0
简单的例子
# 下载xml文件
$ wget https://github.com/databricks/spark-xml/raw/master/src/test/resources/books.xml
import org.apache.spark.sql.SQLContext
val sqlContext = new SQLContext(sc)
val df = sqlContext.read
.format("com.databricks.spark.xml")
.option("rowTag", "book")
.load("books.xml")
val selectedData = df.select("author", "_id")
这里了选择相应的表情进行选择,这里我选择“OBJET_COMPLET”和"LIBELLE",当然路径可以是hdfs的路径,最后你会得到一个DataFrame的类型.
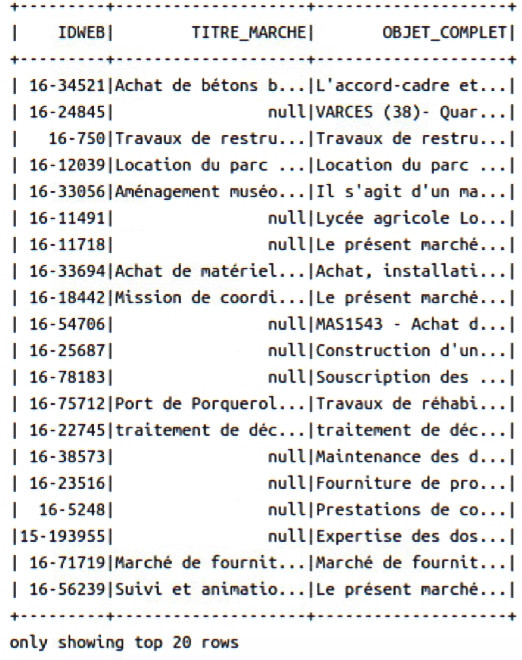
DataFrame 简单理解就是一个数据表,这个数据表中包含着各种数据,错别字等等都会在这里找到,还有null的情况,这些都是要处理掉然后进行学习,学习的目的是找到对应的TOPIC也就是主题。就直接上代码吧,建立一个scala的类。
class LDAml() {
def lda(dataset: DataFrame, sc: SparkContext, inputCol: String,
numbTopic: Int, MaxIterations: Int,
vocabSize: Int) = {
val (documents, vocabArray, model) = preprocess(dataset, inputCol, sc, vocabSize)
val corpus = documents.cache() // use cache
val corpusSize = corpus.count()
/**
* Configure and run LDA
*/
val mbf = {
// add (1.0 / actualCorpusSize) to MiniBatchFraction be more robust on tiny datasets.
2.0 / MaxIterations + 1.0 / corpusSize
}
// running lda
val lda = new LDA()
.setK(numbTopic)
.setMaxIterations(MaxIterations)
.setOptimizer(new OnlineLDAOptimizer().setMiniBatchFraction(math.min(1.0, mbf))) //add optimizer
.setDocConcentration(-1) // use default symmetric document-topic prior
.setTopicConcentration(-1) // use default symmetric topic-word prior
/**
* Print results.
*/
val startTime = System.nanoTime()
val ldaModel = lda.run(corpus)
val elapsed = (System.nanoTime() - startTime) / 1e9
ldaModel.save(sc, sc.getConf.get("spark.client.ldamodelPath"))
/************************************************************************
* Print results. for Zeppelin
************************************************************************/
// Print training time
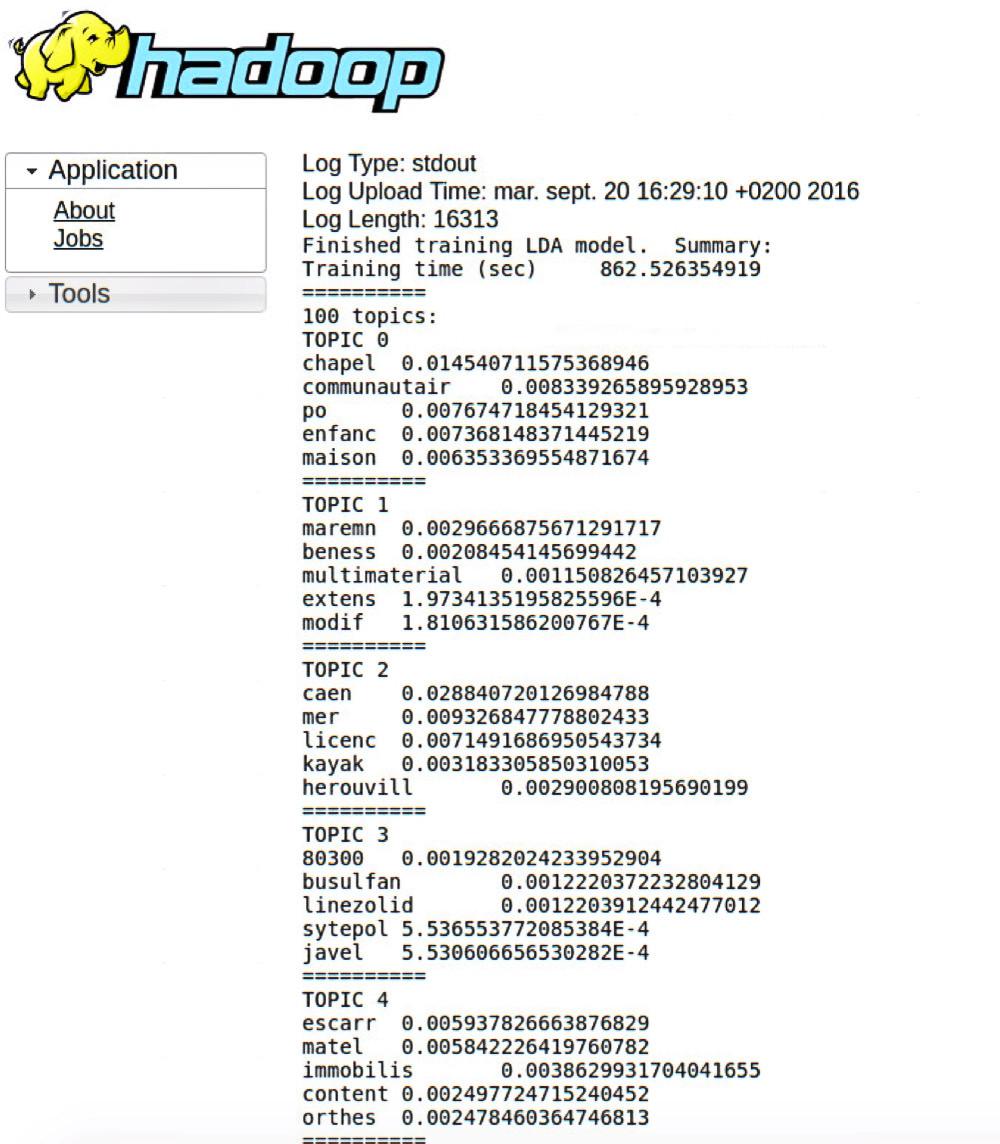
println(s"Finished training LDA model. Summary:")
println(s"Training time (sec)\t$elapsed")
println(s"==========")
// Print the topics, showing the top-weighted terms for each topic.
val topicIndices = ldaModel.describeTopics(maxTermsPerTopic = 5)
val topics = topicIndices.map {
case (terms, termWeights) =>
terms.map(vocabArray(_)).zip(termWeights)
}
println(s"$numbTopic topics:")
topics.zipWithIndex.foreach {
case (topic, i) =>
println(s"TOPIC $i")
topic.foreach { case (term, weight) => println(s"$term\t$weight") }
println(s"==========")
}
}
def preprocess(dataset: DataFrame, inputCol: String, sc: SparkContext, vocabSize: Int): (RDD[(Long, Vector)], Array[String], PipelineModel) = {
val stopWordText1 = sc.textFile(sc.getConf.get("spark.client.stopWordText")).collect().flatMap(_.stripMargin.split("\\s+"))
val stopWordText2 = sc.textFile(sc.getConf.get("spark.client.stopWordText2")).collect().flatMap(_.stripMargin.split("\\s+"))
val data = dataset.na.drop()
// ----------------Pipeline stages---------------------------------------------
// - tokenizer-->stopWordsRemover1-->stemmer-->stopWordRemover2-->AccentRemover
// 简单分词->删除无用词汇->词根->删除无用词汇->删除重音符号
// ----------------------------------------------------------------------------
val tokenizer = new RegexTokenizer()
.setInputCol(inputCol)
.setPattern("[a-z0-9éèêâîûùäüïëô]+")
.setGaps(false)
.setOutputCol("rawTokens")
val stopWordsRemover1 = new StopWordsRemover()
.setInputCol("rawTokens")
.setOutputCol("tokens")
stopWordsRemover1.setStopWords(stopWordsRemover1.getStopWords ++ stopWordText1)
val stemmer = new Stemmer()
.setInputCol("tokens")
.setOutputCol("stemmed")
.setLanguage("French")
val stopWordsRemover2 = new StopWordsRemover()
.setInputCol("stemmed")
.setOutputCol("tokens2")
stopWordsRemover2.setStopWords(stopWordsRemover2.getStopWords ++ stopWordText2)
val accentRemover = new AccentRemover()
.setInputCol("tokens2")
.setOutputCol("mot")
val countVectorizer = new CountVectorizer()
.setVocabSize(vocabSize)
.setInputCol("mot")
.setOutputCol("features")
//------------------------------------------------------
//stage 0,1,2,3,4,5
val pipeline = new Pipeline().setStages(Array(
tokenizer, //stage 0
stopWordsRemover1, //1
stemmer, //2
stopWordsRemover2, //3
accentRemover, //4
countVectorizer //stage 5
))
// creates the PipeLineModel to use for the dataset transformation
val model = pipeline.fit(data)
// countVectorizer stage ==> 5
val vocabArray = model.stages(5).asInstanceOf[CountVectorizerModel].vocabulary
sc.parallelize(vocabArray).saveAsTextFile(sc.getConf.get("spark.client.vocab"))
val documents = model.transform(data)
.select("features")
.rdd
.map { case Row(features: Vector) => features }
.zipWithIndex()
.map(_.swap)
(documents, vocabArray, model)
}
}
最重要的步骤就是 tokenizer-->stopWordsRemover1-->stemmer-->stopWordRemover2-->AccentRemover 处理完成之后,需要transform成dataframe的类型。
这样就可以使用LDA里面的算法进行筛选TOPIC了,这里我选择100个TOPIC迭代100次,这很花时间的。
最后会打印出来。每个TOPIC都是不同的,LDAOptimizer 有两种算法,一种是em算法,一种是online算法,这里选择online算法,因em算法的问题导致之前结果的TOPIC是重复的。